Kafka reassignment 方案
在 Big Data 領域中,Apache Kafka 經常扮演著重要的角色,在敝司 Appier 也不例外。 由於公司業務一直在快速成長,我們需要處理的資料量也是持續增加,對應到 Kafka 則是需要不斷的加入更多機器。 在加入新的機器到 Kafka cluster 後,資料並不會自動轉移到新機器上,而是需要手動的處理,指定每一個 partition 由哪些 broker 負責,這個動作稱為 Partition Reassignment。
Kafka 官方有提供工具 Reassign Partitions Tool 來幫忙產生 partition assignment,然而這個工具最大的缺點是新產生的 assignment 不會去考慮到目前的分佈,搬移時總是在大風吹。這樣做的問題除了需要較長時間才能完成搬移,在搬移時對於 Kafka cluster 產生的負擔也更大。理論上,如果我們只是加入一台新的 broker 進入 cluster,只需要將原先舊的 broker 各自搬一部分 partition 交由新的 broker 負責即可,這樣總共需要搬移的資料量會減少許多,對於執行時間與負擔也會較小。
正因為有這樣的需求,目前有不少現成的工具,不過在開始逐一介紹它們之前,我想要先定義出評斷的標準。這邊我想借用 DataDog 的 Topicmappr 的標準,再補上一點我個人的看法。
- Cluster Storage Rebalancing: 各 broker 的硬碟用量是否一致。有些工具會將 partition 的大小納入考慮,有些則是只考慮數量。
- Constraints Satisfaction Partition Placement: Kakfa 本身支援 Rack Awareness,各 partition 中的每份 replica 必須要遵守一定的規則,避免在單一 Rack (/Zone) 掛掉時,所有的 replica 都一起離線。這個項目用來指出工具是否能產生符合 Rack Awareness 的分配分式。
- Minimal Partition Movement: 是否只搬移必要且儘可能少的 partition。
- Leadership Optimization: 一個 partition 會被存成多份 replica,但其中的 leader 會需要付出更多的資源,因此各 broker 所擔任的 leader 數量最好也能盡量一致。
- Deterministic Output: 當所有條件相同時,每次執行是否會給出相同的結果。對我來說這個指標並不是那麼重要,我更重是的是 "已經搬移完畢的 cluster 再次執行相同工具時,會不會再次進行搬移"。
- Leader Distribution If One Broker Down: Kafka 本身支援 HA,當有 broker 掛掉時,其他 broker 就會接替它 leader 的工作,但剩餘 broker 所分配到的 leader 數量是否也能保持一致呢?
定義好標準之後,那就來評價一下現成的工具吧。
dimas/kafka-reassign-tool
用 Ruby 寫成的小工具,用來產生 assignment JSON file,後續搭配官方工具使用。
文件上並沒有說明所使用的演算法,我粗略從 source code 與註解判斷,覺得應該是簡單的 Greedy 策略。
- Cluster Storage Rebalancing: 不區分 topic,只考慮每個 broker 負責的 partition 數量
- Constraints Satisfaction Partition Placement: 無
- Minimal Partition Movement: 有
- Leadership Optimization: 有,但或許因為是 greedy 策略,實測上有看到分佈得不夠完美的情況。
- Deterministic Output: 有
- Leader Distribution If One Broker Down: 無
SiftScience/kafka-assigner
Java 寫的工具,也是產生 assignment JSON file,我判斷也是 Greedy 策略,但有支援 Rack Awarenewss。
- Cluster Storage Rebalancing: 不區分 topic,只考慮每個 broker 負責的 partition 數量
- Constraints Satisfaction Partition Placement: 有
- Minimal Partition Movement: 有
- Leadership Optimization: 有,但或許因為是 greedy 策略,實測上有看到分佈得不夠完美的情況。
- Deterministic Output: 有
- Leader Distribution If One Broker Down: 無
datadog/kafka-kit/topicmappr
使用 Go 所開發,同樣產生 assignment JSON file,使用的演算法是 First-fit-decreasing bin packing。
比較特別的是 topicmappr 可以選擇 placement strategy,選擇 count 時那就跟其他工具差不多,只考慮 partition 的數量;但選擇 storage 時,則會針對每個 partition 的大小進行安排。當使用 storage placement 時,工具會從 ZooKeeper 的特定 endpoint 來取得 partition 資訊,而這些 endpoint 則會需要額外的工具來更新。
- Cluster Storage Rebalancing: 可以選擇使用 storage 和 count 兩種策略。
- Constraints Satisfaction Partition Placement: 有
- Minimal Partition Movement: 有
- Leadership Optimization: 有,但實測上有看到分佈得不夠完美的情況。
- Deterministic Output: 有
- Leader Distribution If One Broker Down: 無
everpeace/kafka-reassign-optimizer
這工具是將 reassignment 問題轉成 Mixed Integer Programming 並透過 lp_solve 解決。 使用 Scala 實作,工具在搬移時是直接對 Kafka 進行操作,不需要再透過官方工具,並且支援 batch,可以控制每個 batch 所搬移的 partition 數量。 這工具並不支援 throttle,不過其實 throttle 可以使用 Kafka config 進行控制,所以我會另外準備一份 Shell script 來控制 throttle,搭配這個工具使用。
沒有支援 "Leadership Optimization" 是這個演算法較大的缺陷。 此外要注意的是,當 cluster 規模較大時,這工具將會遭遇 OutOfMemoryError 問題而無法使用。 不過除了使用內建的演算法外,這工具也支援從外部提供 assignment JSON file,因此也可以使用前述的任何一項工具來產生 assignment file,並透過這工具來進行搬移,藉此享受到 batch 帶來的好處,而不用擔心同時搬移過多 partition 時,可能會造成 cluster loading 過重的問題。
- Cluster Storage Rebalancing: 不區分 topic,只考慮每個 broker 負責的 partition 數量
- Constraints Satisfaction Partition Placement: 無
- Minimal Partition Movement: 有
- Leadership Optimization: 無
- Deterministic Output: 有
- Leader Distribution If One Broker Down: 無
我過去的作法
在許多年前我曾使用過 SiftScience/kafka-assigner 一段時間,其中最無法滿足我需求的是 "Leader Distribution If One Broker Down" 這項目。 事實上這個指標正是我自己加進去的,目前其他工具似乎都並沒有考量這個需求。 前述的工具大都能夠在所有機器健康時,儘可能讓每一台機器擔任相同數量的 leader。 但當你在管理像 Kafka 這樣的分散式系統時,免不了會遇到機器故障下線的情況,這導致該機器負責的 partition 需要由其他機器擔任 leader 的情況,而我希望在這種情況下,剩餘機器擔任 leader 的數量,仍然要儘可能一致。
我提出的解決方案是自己設計這套演算法,背後的想法很簡單,事先根據 broker 數量與 replication factor,列出所有可能的 assignment 的排列組合,以 broker 數量為 4,replication factor=2 為例,所有可能的 assignment 如下:
(1,2) (2,3) (3,4) (4,1)
(1,3) (2,4) (3,1) (4,2)
(1,4) (2,1) (3,2) (4,3)
接著根據 partition 的數量,依序從這些組合中取出使用,例如當 partition 數量為 3 時,那就會對應到 (1,2), (2,3), (3,4)。如果 partition 數量超過組合數,那就從頭再取一輪即可。 按照這個順序進行安排,不只可以確保 leader 的數量是平均分佈的,當其中一個機器故障時,其他機器分配到的 leader 數量也會是平均的。
現在我們已經決定好所有 partition 將會使用的 assignment,但並不是直接依序對應,因為如果這樣做的話,每次需要增減機器時,大多數的 partition 都會需要搬移,將會破壞掉 "Minimal Partition Movement" 這項需求。我們對應的方案是找出儘可能少 partition 搬移量的安排方式,而具體的解法則是建立一個 Bipartite Graph,左邊的節點是現有的 assignment,右邊的節點則是將要使用的 assignment,將 edge weight 設定為搬移量,將問題轉化成 Minimum Weight Perfect Bipartite Matching,而這問題可以使用 Kuhn-Munkres algorithm 來解。
也就是說我們事先不去考慮原有 assignment 的情況,而是在產出出新的 assignment 之後,再利用 Bipartite Matching 找出較少搬移的對應方式。 這方案在機器數量較低時確實還不錯,因為排列組合的數量並不多,現有的 assignment 和未來的 assignment 有很高的重複性,實際需要進行搬移的 partition 數量並不多。 後續我真的使用的了這方案持續了數年,但是當機器數量增加到一定數量後,呈幾何級數增長的排列組合,會讓需要搬移的 partition 數量大幅增加,這也是我最終放棄這方案的主因。
- Cluster Storage Rebalancing: 不區分 topic,只考慮每個 broker 負責的 partition 數量,在 worst-case 比其他工具差了一些。
- Constraints Satisfaction Partition Placement: 無
- Minimal Partition Movement: broker 數量少時還可接受,數量多時則效果不佳
- Leadership Optimization: 有
- Deterministic Output: 有
- Leader Distribution If One Broker Down: 有
Pinterest 的演算法
在尋找新的解決方案時,我注意到了 Pinterest 的系列文章 "Using graph algorithms to optimize Kafka operations" (Part 1 & Part 2)。 跟前述的工具不同的是,這兩篇文章只講述了演算法而沒有提供現成工具,並且它並不會對資料進行搬移,僅靠改變 assignment 中的順序,來達成 "Leader Optimization"。
這裡使用的技巧是將問題轉成 Maximum Flow,接著就可以使用現成的演算法,例如 Edmonds-Karp 或著 Dinic's 來解。 建構 flow network 的細節我就不說了,請自行閱讀原文。大致就是將 leader 負擔較重的 broker 放在左側,負擔較輕的則放在右側,並試著從中找出 "flow",將部份 leader 的責任從左側轉交給右側,藉此達成平衡。
以下圖為例,共有四個 partition,其中 leader 指向 partition 標記為藍色,partition 則指向剩餘的 replica。
p1: [1,2,3]
p2: [2,3,4]
p3: [1,2,3]
p4: [2,1,3]
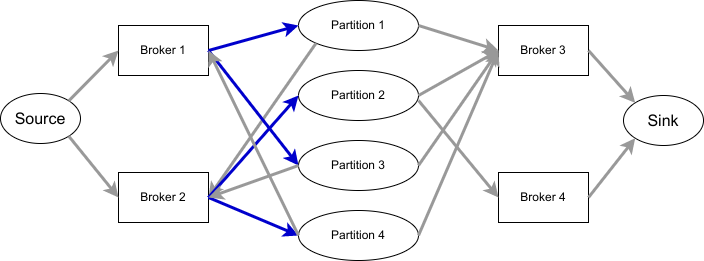
在加入了原文中提到的兩個 residue node,並且有正確處理好浮點數誤差之後,在我準備的數百組測試資料中,這個演算法都可以產出最佳的結果。 我過去有參與程式競賽的經驗,也確實有使用 Maximum Flow 來解題的情況,但並沒有遇過類似的題目,而引入 residue node 的技巧更是聞所未聞,因此嘗試這個演算法對我來說也是個很新奇的體驗。
由於 Pinterest 的演算法只能平衡 leader 的數量,並不會真的搬移資料,因此在加入新的機器或移除舊機器時時,還是需要其他工具的配合。 我也很好奇 Pinterest 是怎麼解決這問題,Pinterest 針對 Kafka 的管理,陸續推出了兩套工具 DoctorK 和 Onion,然而我在這兩套工具中,都沒有看到這份演算法的使用。
延伸到 partition
現在平衡 leader 的演算法有了,我只要再找出能夠將 partition 平均分散到所有機器的方法就可以了。 看著現有的演算法,我不禁思索如果我將建構 flow 的方式調整一下,是不是也能夠用來解這問題。
這次我們不是考慮 leader,而是考慮每個 broker 上負責的 partition 數量,將負擔過重的 broker 放左側,其餘的放右側。 如果 broker 存在 replica 中,就用箭頭指向對應的 partition (標示成藍色,表示這份 partition 可以考慮從這台 broker 移出)。再從 partition 指到剩餘的所有 broker (表示可以將 partition 改放到這些 broker)。如下圖所示:
p1: [1,2,3]
p2: [2,1,4]
p3: [1,2,4]
p4: [2,1,3]
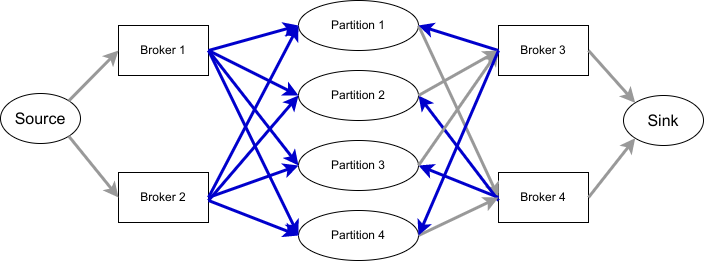 |
|---|
| 上圖省略了 residue node |
經過我的測試資料實測後,這個演算法確實適用,並且產生的結果也都是最佳的。
甚至如果想要增加 replication factor 也是做得到的,只要新增一個節點指向所有 partition,並適當調整每一個 edge 的 capacity 即可,如下圖。
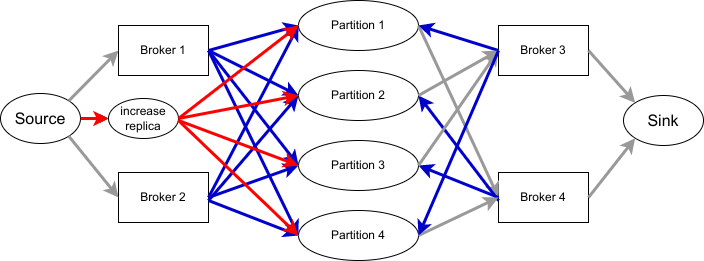 |
|---|
| 上圖省略了 residue node |
至於減少 replication factor,原先我也想靠新增一個節點在 sink 側來達成,實測卻發現在某些案例不會成功,因為可能會遇到 partition 的所有 replica 都在右側的情況。 目前的方案還無法支援 Rack Awareness,但只要建構出適當的 flow network,其實也是可以滿足需求的。
只要我們先使用這個演算法,就可以將 partition 平均分佈到各機器上。接著再執行 Pinterest 原本的演算法,就可以在不做額外資料搬移的情況下,讓 leader 的分佈也更加平均,聽起來不錯吧。
再延伸到 1st-follower
現在只剩最後一個需求尚未滿足了,我希望在某個 broker 掛掉之後,他所扮演的 leader 也能平均分散給其他 broker。 要達成這件事,其實就是要讓 assignment 中的前兩個元素,即 (leader, 1st-follower) 盡可能的平均分佈。 因此我們在產生了先前的結果之後,再多執行一次演算法,希望能達成這個需求。
這次的方案不能夠進行資料搬移,也不能改變 leader,只能改變 1st-follower,否則會破壞前兩次演算法的結果。 這次建構的 flow network 會將 broker 換成 broker pair,原先的 (leader, 1st-follower) 指向 partition,partition 再指向 (leader, 其餘的 follower)。如下圖所示:
p1: 1,2,3
p2: 2,1,4
p3: 1,2,4
p4: 2,1,3
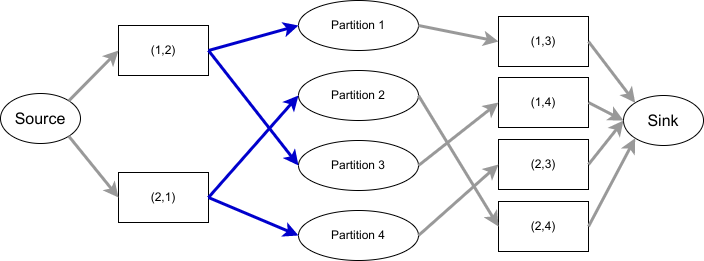 |
|---|
| 上圖省略了 residue node |
這次的方案只適用於 replication factor 大於 2 的情境,並且沒有辦法讓 (leader, 1st-follower) 在所有的測試資料中都達成完美的分佈,但相較於一開始的分佈還是能改善許多,所以我想這仍然能算是一個不錯的 heuristic 策略。
總結
在連續套用同一個演算法三次,並且依序解決了三種需求後,我們總算得到了一個似乎還不錯的方案。
有點可惜的是,即使在已經處理過、且分佈得很平均的情況下,再次執行演算法仍然會得到需要搬移的指示,我認為這是 residue node 帶來的副作用。 幸好只要在執行演算法之前先主動判斷一下目前的分配是否已經完美,只有在還有改進空間時才執行即可。
- Cluster Storage Rebalancing: 不區分 topic,只考慮每個 broker 負責的 partition 數量
- Constraints Satisfaction Partition Placement: 有
- Minimal Partition Movement: 有
- Leadership Optimization: 有
- Deterministic Output: 無,但可以加上額外檢查來排除。
- Leader Distribution If One Broker Down: 有
雖然得到了一個不錯的成果,這個方案在正確性方面卻還是讓我有些擔心,雖然在我隨機產生的數百個測試資料中都能跑出完美的結果,但這終究沒有數學證明支持,或許會在極端情況下遇到例外。 不過目前作為一個 operation 工具使用,我想也是夠用了。很高興在工作上能遇到這樣的挑戰,並最終提出了一個有趣的解決方案。